Datasets
Organize views and define relationships
A dataset is a collection of views and the relationships between them, defining the structured tables that users interact with when querying data from the catalog in the canvas.
Datasets should be designed to serve a business objective or function. This approach ensures that datasets are meaningful, actionable, and aligned with business needs.
Each dataset is stored in a separate YAML file and can be built using one or more views. There are two ways to specify the views for a dataset:
- using
fromandjointo define the joins in the dataset; or - using
viewswhich requires that the joins are defined in the views.
Regardless of where they are defined, the joins must be given join types (e.g., one-to-many, many-to-one) to ensure correct aggregation and maintain symmetrical data aggregation.
Once configured, datasets automatically generate SQL based on predefined logic, enabling accurate and consistent data exploration within the canvas.
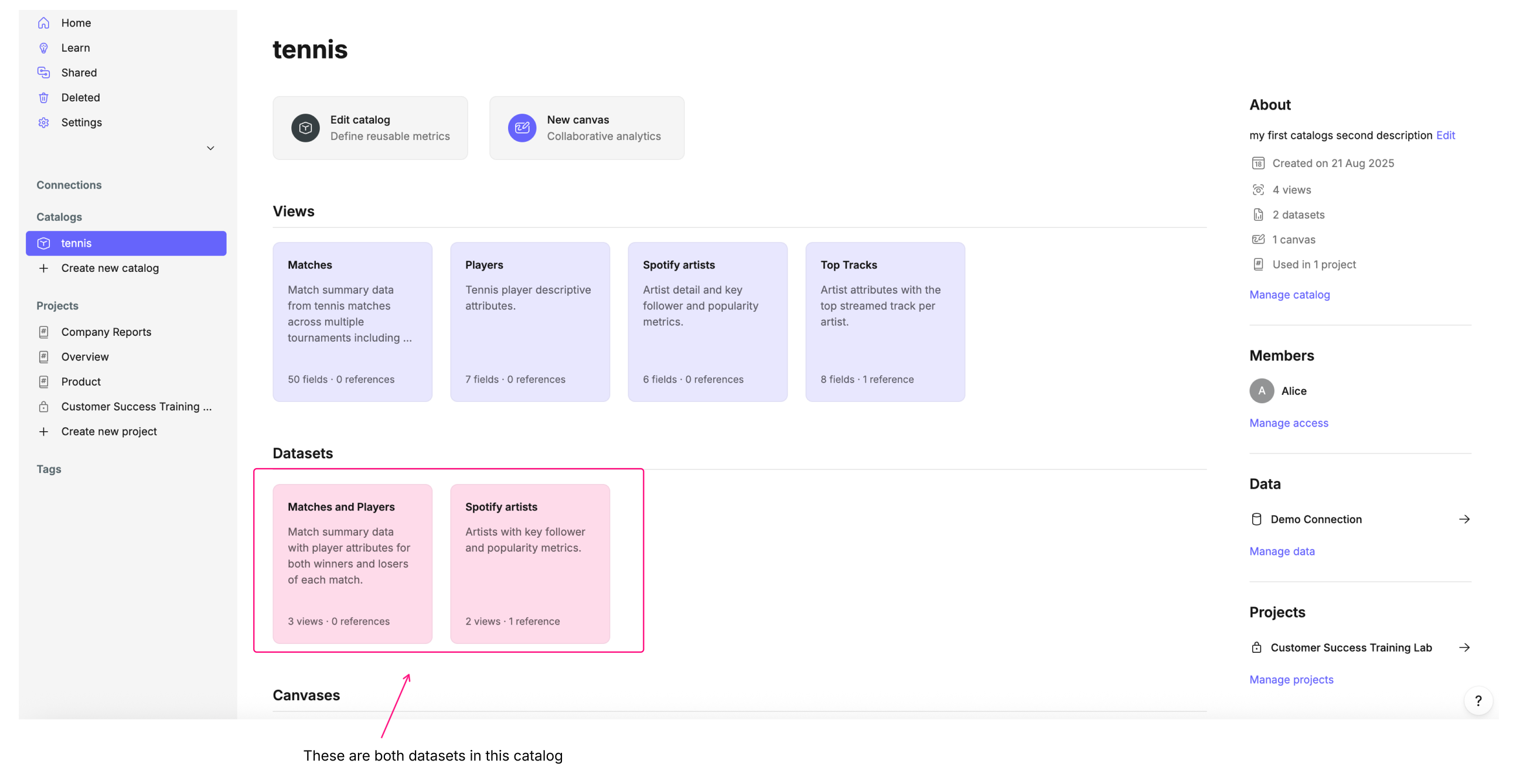
Datasets are listed in the Datasets section of the catalog YAML editor.

They can also be seen in the catalog homepage.
Dataset YAML schema
name: matches_and_players
label: Matches and Players
description: Match summary data with player attribution for both winners and losers of each match.
from: matches_partitioned
join:
- view: players
alias: winners
label: winners
constraint: winners.player_id = matches_partitioned.winner_id
relationship: many_to_one
- view: players
alias: losers
label: losers
constraint: winners.player_id = matches_partitioned.loser_id
relationship: many_to_oneSee the customizing datasets page to learn about how to customise the dataset YAML.