Introduction to dbt
dbt is an open-source tool for transforming data and helping to build and define DAG (network) of SQL queries - these are called models.
In Count, dbt models can be added as cells, meaning the canvas can be used to explore and develop your dbt models.
Count supports dbt Cloud and dbt Core integrations, learn more about setting up your dbt integration here.
Key features
1. Data cells are reactive - Count features a dynamic query complication engine which complies SQL for each cell, sends it to the appropriate database, then renders the result, harnessing the speed of modern cloud data warehouses.
2. Explode CTEs - clicking the 'explosion' button will automatically take CTEs and represent them as connected cells, making it simple to understand and debug your query.
3. Local cells - Count ships with a local database built on DuckDB. Choosing this option as your datasource reduces the load on your database leading to faster results.
4. Caching - use caching to improve data retrieval performance.
5. Export SQL (and convert it to Jinja) - customise the number of upstream cells included in exported SQL by selectively treating cells as dbt models.
6. Show compiled SQL - see exactly what SQL is being run to identify issues faster.
Use cases
When using the dbt integrations, there are a number of key use cases, which can be split into three main areas, let's explore each of these further.
Technical use case
There are lots of practical use cases for using dbt, these include:
1. Debugging - import your existing models into Count to visualize linage, making it easy to spot errors and debug collaboratively.
2. Database comparisons - compare different databases and and merge changes, helping you to debug, and understand data flows and migrations, all in one place.
3. Data engineering prototyping - develop faster by prototyping with sample data before building out full production models.
4. Design and develop new data models - build new dbt models in Count and commit directly to Github.
Collaboration with model consumers
There are two main use cases when it comes to collaborating with model consumers:
1. Model exposure - you can create data discovery canvases which maps out and helps others find relevant data. This makes it easy to compare queries across different environments (e.g. production versus development).
2. High level end-to-end data flow - visualize data flows in canvases to build trust by showing how information flows through systems, breaking down silos and enabling direct collaboration on model building.
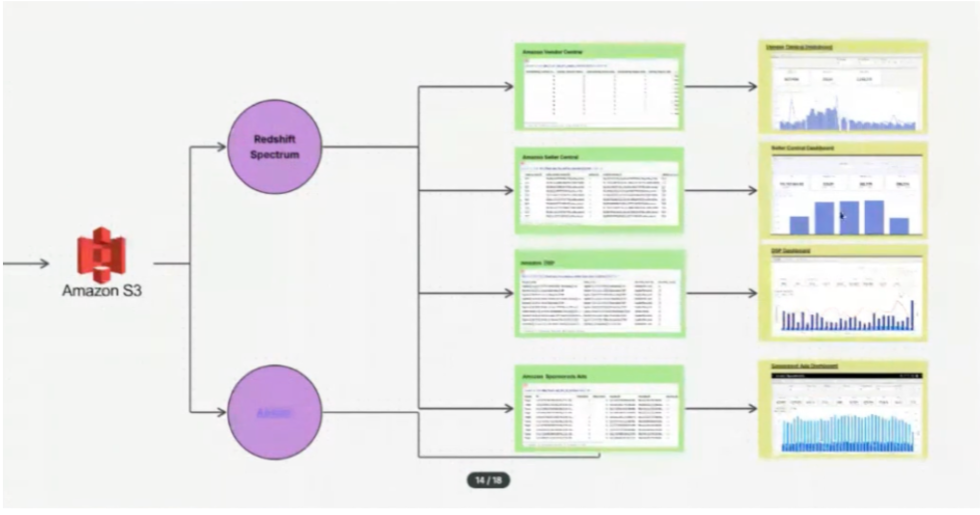
Organization and documentation
Using dbt at Count can also help with organisation and documentation:
1. Organizing dbt models - layout all your models in a canvas to seamlessly share data structures and show models alongside raw data in a data lake.
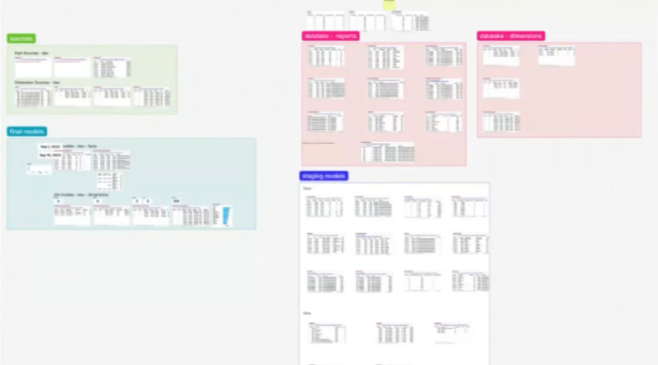
2. Tests - when using dbt Cloud, model test results are available within the canvas. If a test begins to fail, the canvas is a great place to diagnose, debug, and document model failures.
3. Documenting dbt exposures - build interactive, richer documentation to convey dbt models to less technical BI tool users with ease.
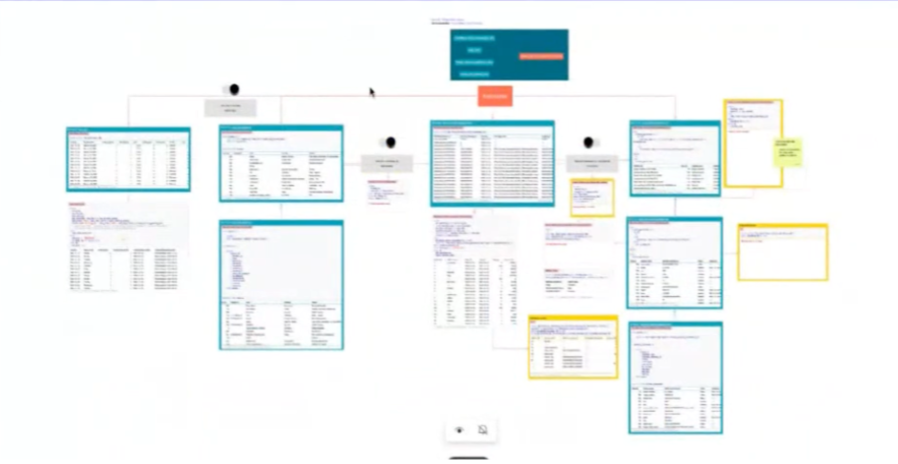
4. Laying out data models - the 2D nature of the canvas makes it a natural place to visually represent your model DAG. Arrange your models logically in space to better represent the logical data flow.
Get started with dbt by following our dbt integration guide.